06 October 2023
A serverless system
One of the services that our team inherited from previous team was an outbound messaging system, via WhatsApp. It spent most of it’s time sending out messages. The ratio of inbound messages to outbound messages was almost around 1:4. When the system was built the volume of messages were low we had only one provider for using WhatsApp APIs. Fast forward and our volume of outbound messages more than doubled and we are also looking at extra providers, we anyway had ended up with 2 at that time. Furthermore, we had outbound messages going via three numbers. The request count on each number was not the same, the volume varied greatly between numbers. There were API call limits as well
Summarising them we had the below requirements
- Scale different vendor API calls differently
- Throttle different vendors differently
- Add more phone numbers (via existing or new vendors)
- Prepare data for each vendor differently
Now looking at the data flow we have an image like below
All the three steps were within the current application.
The only issue with the above image is that the Send step is more verbose in code than drawn out to be.
APIs of different providers work differently, there is no standard behavior. Not to mention the existing code has been written without any modularisation, so we are left with a huge file with lot of if conditions thrown here and there.
We needed to clean this up.
Considering all the above and do not wanting to spend too much time refactoring the existing code, we decided to opt for AWS Serverless. Although this puts us in a tight situation were we are locked in with the vendor - we were already building systems on top of AWS Serverless. There was no plan to migrate away any time soon. Furthermore, we plan to keep the code modular so in case of need we could easily move it.
We built an architecture like below
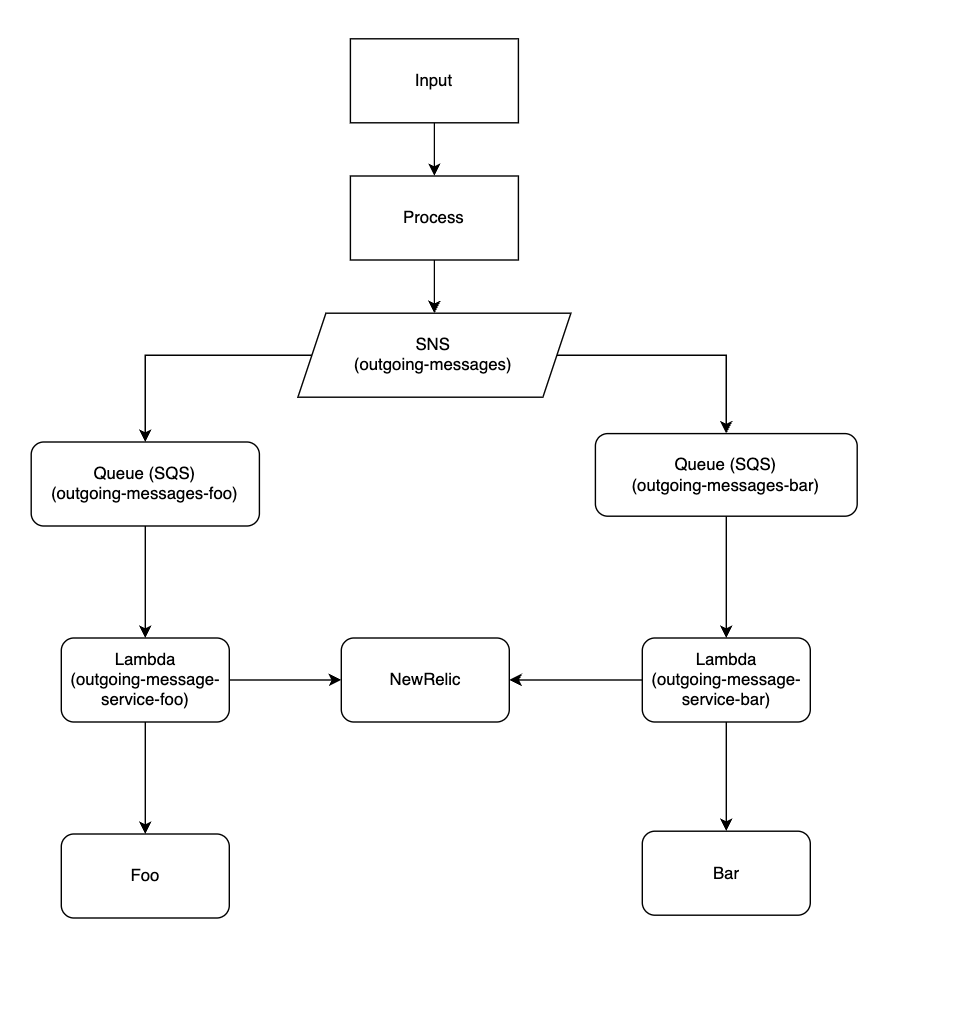
What we essentially did was move out the Send part in detail to a new system, where we could have control yet not worry much about the plumbing.
To set this architecture we needed to create the following resources
- 1 SNS Topic ->
outgoing-messages - 2 SQS Queues ->
ougoing-messages-foo&outgoing-messags-bar - 2 Lambdas ->
outgoing-message-service-foo&outgoing-message-service-bar
The crux of redirection here is now handled by SNS and SQS. They provide a message filtering capability in which we can selectively listen in a queue from a certain topic. A sample AWS command to get that done will look like below
# Subscribe the queue to the topic
aws sns subscribe \
--topic-arn arn:aws:sns:ap-south-1:000000000000:outgoing-messages \
--protocol sqs \
--notification-endpoint arn:aws:sqs:ap-south-1:000000000000:outgoing-messages-foo
# Add a filtering policy
aws sns set-subscription-attributes \
--subscription-arn arn:aws:sns:ap-south-1:000000000000:outgoing-messages:4b0aa0aa-ed4c-4da3-a69d-46df2b422602 \
--attribute-name FilterPolicy \
--attribute-value "{\"target\":\"FOO\"}"
This can also be done from the AWS Console UI. What is happening here is that we are adding a subscription to SNS from the specific SQS and then adding a filtering parameter. The parameter we have added is in JSON format
{ "target": "FOO" }
With this, if the message body has the key and value as specified, it gets routed to the specific SQS. Hence, we need not worry about routing here. It’s taken care of.
The flow will be as follows
- First publish the message to the SNS topic
outgoing-messages - Depending on the filtering parameter it gets pushed specific SQS queue
- The corresponding lambda will act when a message arrives.
Looking back at the requirements we had we are able to achieve the below as follows:
1. Scale different vendor API calls differently
We can control the number of lambdas that needs to be running concurrently setting the “Maximum Concurrency”. Considering one lambda function invocation per message.
The launch of maximum concurrency for SQS as an event source allows you to control Lambda function concurrency per source. You set the maximum concurrency on the event source mapping, not on the Lambda function.
Reference: here
2. Throttle different vendors differently
Similar to above, we can get hold of “Maximum Concurrency” here again and make sure we only consume “x” number of messages concurrently, there by making sure concurrency differs for different vendor.
3. Add more phone numbers (via existing or new vendors)
We could simply expand the architecture by adding one more queue. Add one more filter param. For example we actually implemented it with a filter param like below
{ "target": "FOO-PRIMARY" }
We built another SQS queue with a similar name as well
outgoing-messages-foo-primary
4. Prepare data for each vendor differently
We noticed the API signature and even behaviour of each vendor where different. Hence, we created lambdas for each vendor, with specific code as required. To share an instance the error handling ie. the error codes returned were different for each vendor, hence we had to do the error handling differently for each. This way, it was easier to deploy one more number, or handle failures when some API change was introduced by vendors without needing to touch the other lambdas.
All this were implemented using CDK and hence it was completely code driven.
Conclusion
It was a project that did not come with any specification. There was a requirement and some pain points shared by the team and it was evident we needed to overhaul the system. Looking at the existing code and system, it was not possible to rewrite the part due to various constraints of time and code quality.
Fin.